 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCityTrajBench: A Unified Benchmark for City-Scale Vehicle Trajectory Generation
Jun 01, 2026Urban trajectory generation is a fundamental task for transportation simulation, urban planning, and mobility analytics. However, systematic comparison across trajectory generation methods remains difficult because existing studies often rely on different datasets, preprocessing pipelines, trajectory representations, and evaluation metrics. This fragmentation makes it unclear whether reported performance differences arise from the generation mechanism itself or from inconsistent experimental protocols. To address this issue, we present CityTrajBench, a unified benchmark framework and protocol for city-scale vehicle trajectory generation. CityTrajBench standardizes data ingestion, trajectory normalization, feature construction, model adaptation, map-aware post-processing, model selection, and multi-level evaluation under a common setting. It supports heterogeneous generators, including statistical baselines, VAE-based, GAN-based, diffusion-based, and flow-matching-based models, and evaluates them on three real-world urban trajectory datasets. The benchmark measures global spatial realism, trip-level distribution fidelity, trajectory-level geometric similarity, conditional mobility consistency, and efficiency. Experiments reveal clear trade-offs across model families: DiffTraj is strongest on trajectory-level geometric fidelity, DiffRNTraj is competitive on structure-sensitive global realism, and TrajFlow provides a strong balance across realism, quality, conditional consistency, and efficiency. Meanwhile, a simple Markov baseline remains competitive on coarse-grained trip and local-movement statistics. These findings show that urban trajectory generation quality is inherently multi-objective, that no single model dominates all criteria equally, and that CityTrajBench provides a reproducible benchmark protocol and testbed for future research on urban mobility generation.
A unified foundational framework for knowledge injection and evaluation of Large Language Models in Combustion Science
Feb 27, 2026To advance foundation Large Language Models (LLMs) for combustion science, this study presents the first end-to-end framework for developing domain-specialized models for the combustion community. The framework comprises an AI-ready multimodal knowledge base at the 3.5 billion-token scale, extracted from over 200,000 peer-reviewed articles, 8,000 theses and dissertations, and approximately 400,000 lines of combustion CFD code; a rigorous and largely automated evaluation benchmark (CombustionQA, 436 questions across eight subfields); and a three-stage knowledge-injection pathway that progresses from lightweight retrieval-augmented generation (RAG) to knowledge-graph-enhanced retrieval and continued pretraining. We first quantitatively validate Stage 1 (naive RAG) and find a hard ceiling: standard RAG accuracy peaks at 60%, far surpassing zero-shot performance (23%) yet well below the theoretical upper bound (87%). We further demonstrate that this stage's performance is severely constrained by context contamination. Consequently, building a domain foundation model requires structured knowledge graphs and continued pretraining (Stages 2 and 3).
PoseCraft: Tokenized 3D Body Landmark and Camera Conditioning for Photorealistic Human Image Synthesis
Feb 22, 2026Digitizing humans and synthesizing photorealistic avatars with explicit 3D pose and camera controls are central to VR, telepresence, and entertainment. Existing skinning-based workflows require laborious manual rigging or template-based fittings, while neural volumetric methods rely on canonical templates and re-optimization for each unseen pose. We present PoseCraft, a diffusion framework built around tokenized 3D interface: instead of relying only on rasterized geometry as 2D control images, we encode sparse 3D landmarks and camera extrinsics as discrete conditioning tokens and inject them into diffusion via cross-attention. Our approach preserves 3D semantics by avoiding 2D re-projection ambiguity under large pose and viewpoint changes, and produces photorealistic imagery that faithfully captures identity and appearance. To train and evaluate at scale, we also implement GenHumanRF, a data generation workflow that renders diverse supervision from volumetric reconstructions. Our experiments show that PoseCraft achieves significant perceptual quality improvement over diffusion-centric methods, and attains better or comparable metrics to latest volumetric rendering SOTA while better preserving fabric and hair details.
CADGrasp: Learning Contact and Collision Aware General Dexterous Grasping in Cluttered Scenes
Jan 21, 2026Dexterous grasping in cluttered environments presents substantial challenges due to the high degrees of freedom of dexterous hands, occlusion, and potential collisions arising from diverse object geometries and complex layouts. To address these challenges, we propose CADGrasp, a two-stage algorithm for general dexterous grasping using single-view point cloud inputs. In the first stage, we predict sparse IBS, a scene-decoupled, contact- and collision-aware representation, as the optimization target. Sparse IBS compactly encodes the geometric and contact relationships between the dexterous hand and the scene, enabling stable and collision-free dexterous grasp pose optimization. To enhance the prediction of this high-dimensional representation, we introduce an occupancy-diffusion model with voxel-level conditional guidance and force closure score filtering. In the second stage, we develop several energy functions and ranking strategies for optimization based on sparse IBS to generate high-quality dexterous grasp poses. Extensive experiments in both simulated and real-world settings validate the effectiveness of our approach, demonstrating its capability to mitigate collisions while maintaining a high grasp success rate across diverse objects and complex scenes.
Benchmarking neural surrogates on realistic spatiotemporal multiphysics flows
Dec 21, 2025Predicting multiphysics dynamics is computationally expensive and challenging due to the severe coupling of multi-scale, heterogeneous physical processes. While neural surrogates promise a paradigm shift, the field currently suffers from an "illusion of mastery", as repeatedly emphasized in top-tier commentaries: existing evaluations overly rely on simplified, low-dimensional proxies, which fail to expose the models' inherent fragility in realistic regimes. To bridge this critical gap, we present REALM (REalistic AI Learning for Multiphysics), a rigorous benchmarking framework designed to test neural surrogates on challenging, application-driven reactive flows. REALM features 11 high-fidelity datasets spanning from canonical multiphysics problems to complex propulsion and fire safety scenarios, alongside a standardized end-to-end training and evaluation protocol that incorporates multiphysics-aware preprocessing and a robust rollout strategy. Using this framework, we systematically benchmark over a dozen representative surrogate model families, including spectral operators, convolutional models, Transformers, pointwise operators, and graph/mesh networks, and identify three robust trends: (i) a scaling barrier governed jointly by dimensionality, stiffness, and mesh irregularity, leading to rapidly growing rollout errors; (ii) performance primarily controlled by architectural inductive biases rather than parameter count; and (iii) a persistent gap between nominal accuracy metrics and physically trustworthy behavior, where models with high correlations still miss key transient structures and integral quantities. Taken together, REALM exposes the limits of current neural surrogates on realistic multiphysics flows and offers a rigorous testbed to drive the development of next-generation physics-aware architectures.
ClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes
Jun 17, 2025
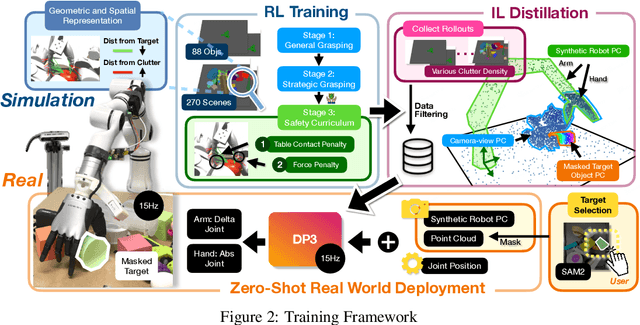


Dexterous grasping in cluttered scenes presents significant challenges due to diverse object geometries, occlusions, and potential collisions. Existing methods primarily focus on single-object grasping or grasp-pose prediction without interaction, which are insufficient for complex, cluttered scenes. Recent vision-language-action models offer a potential solution but require extensive real-world demonstrations, making them costly and difficult to scale. To address these limitations, we revisit the sim-to-real transfer pipeline and develop key techniques that enable zero-shot deployment in reality while maintaining robust generalization. We propose ClutterDexGrasp, a two-stage teacher-student framework for closed-loop target-oriented dexterous grasping in cluttered scenes. The framework features a teacher policy trained in simulation using clutter density curriculum learning, incorporating both a novel geometry and spatially-embedded scene representation and a comprehensive safety curriculum, enabling general, dynamic, and safe grasping behaviors. Through imitation learning, we distill the teacher's knowledge into a student 3D diffusion policy (DP3) that operates on partial point cloud observations. To the best of our knowledge, this represents the first zero-shot sim-to-real closed-loop system for target-oriented dexterous grasping in cluttered scenes, demonstrating robust performance across diverse objects and layouts. More details and videos are available at https://clutterdexgrasp.github.io/.
Sample Complexity and Representation Ability of Test-time Scaling Paradigms
Jun 05, 2025Test-time scaling paradigms have significantly advanced the capabilities of large language models (LLMs) on complex tasks. Despite their empirical success, theoretical understanding of the sample efficiency of various test-time strategies -- such as self-consistency, best-of-$n$, and self-correction -- remains limited. In this work, we first establish a separation result between two repeated sampling strategies: self-consistency requires $\Theta(1/\Delta^2)$ samples to produce the correct answer, while best-of-$n$ only needs $\Theta(1/\Delta)$, where $\Delta < 1$ denotes the probability gap between the correct and second most likely answers. Next, we present an expressiveness result for the self-correction approach with verifier feedback: it enables Transformers to simulate online learning over a pool of experts at test time. Therefore, a single Transformer architecture can provably solve multiple tasks without prior knowledge of the specific task associated with a user query, extending the representation theory of Transformers from single-task to multi-task settings. Finally, we empirically validate our theoretical results, demonstrating the practical effectiveness of self-correction methods.
Adaptive Visuo-Tactile Fusion with Predictive Force Attention for Dexterous Manipulation
May 20, 2025Effectively utilizing multi-sensory data is important for robots to generalize across diverse tasks. However, the heterogeneous nature of these modalities makes fusion challenging. Existing methods propose strategies to obtain comprehensively fused features but often ignore the fact that each modality requires different levels of attention at different manipulation stages. To address this, we propose a force-guided attention fusion module that adaptively adjusts the weights of visual and tactile features without human labeling. We also introduce a self-supervised future force prediction auxiliary task to reinforce the tactile modality, improve data imbalance, and encourage proper adjustment. Our method achieves an average success rate of 93% across three fine-grained, contactrich tasks in real-world experiments. Further analysis shows that our policy appropriately adjusts attention to each modality at different manipulation stages. The videos can be viewed at https://adaptac-dex.github.io/.
Boosting Universal LLM Reward Design through the Heuristic Reward Observation Space Evolution
Apr 10, 2025Large Language Models (LLMs) are emerging as promising tools for automated reinforcement learning (RL) reward design, owing to their robust capabilities in commonsense reasoning and code generation. By engaging in dialogues with RL agents, LLMs construct a Reward Observation Space (ROS) by selecting relevant environment states and defining their internal operations. However, existing frameworks have not effectively leveraged historical exploration data or manual task descriptions to iteratively evolve this space. In this paper, we propose a novel heuristic framework that enhances LLM-driven reward design by evolving the ROS through a table-based exploration caching mechanism and a text-code reconciliation strategy. Our framework introduces a state execution table, which tracks the historical usage and success rates of environment states, overcoming the Markovian constraint typically found in LLM dialogues and facilitating more effective exploration. Furthermore, we reconcile user-provided task descriptions with expert-defined success criteria using structured prompts, ensuring alignment in reward design objectives. Comprehensive evaluations on benchmark RL tasks demonstrate the effectiveness and stability of the proposed framework. Code and video demos are available at jingjjjjjie.github.io/LLM2Reward.
Amodal3R: Amodal 3D Reconstruction from Occluded 2D Images
Mar 17, 2025Most image-based 3D object reconstructors assume that objects are fully visible, ignoring occlusions that commonly occur in real-world scenarios. In this paper, we introduce Amodal3R, a conditional 3D generative model designed to reconstruct 3D objects from partial observations. We start from a "foundation" 3D generative model and extend it to recover plausible 3D geometry and appearance from occluded objects. We introduce a mask-weighted multi-head cross-attention mechanism followed by an occlusion-aware attention layer that explicitly leverages occlusion priors to guide the reconstruction process. We demonstrate that, by training solely on synthetic data, Amodal3R learns to recover full 3D objects even in the presence of occlusions in real scenes. It substantially outperforms existing methods that independently perform 2D amodal completion followed by 3D reconstruction, thereby establishing a new benchmark for occlusion-aware 3D reconstruction.